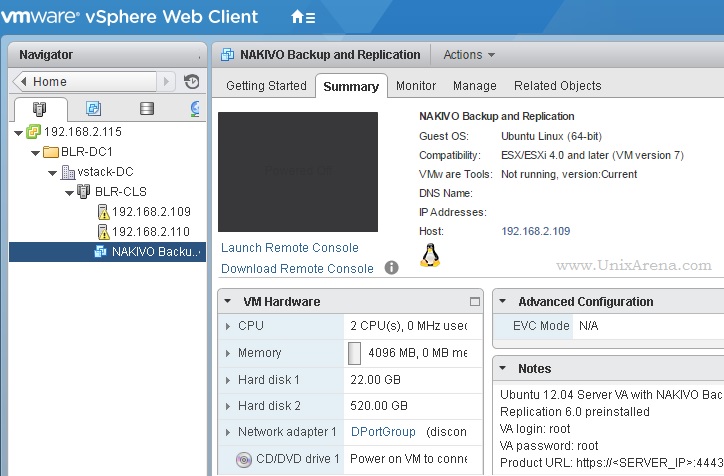
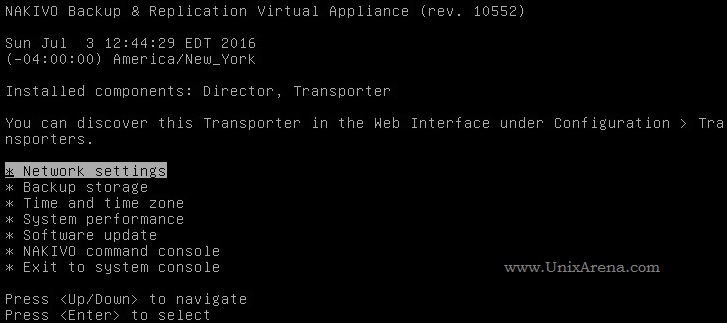
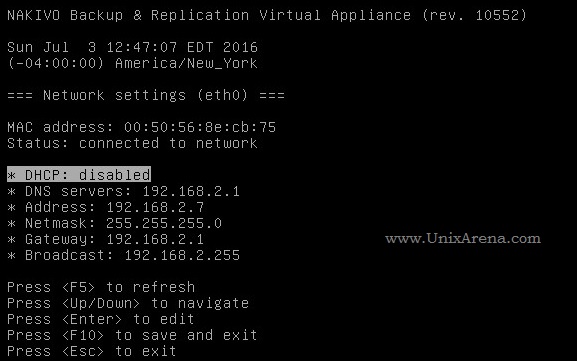
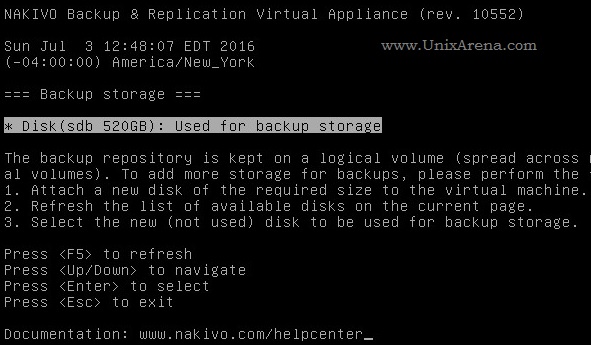
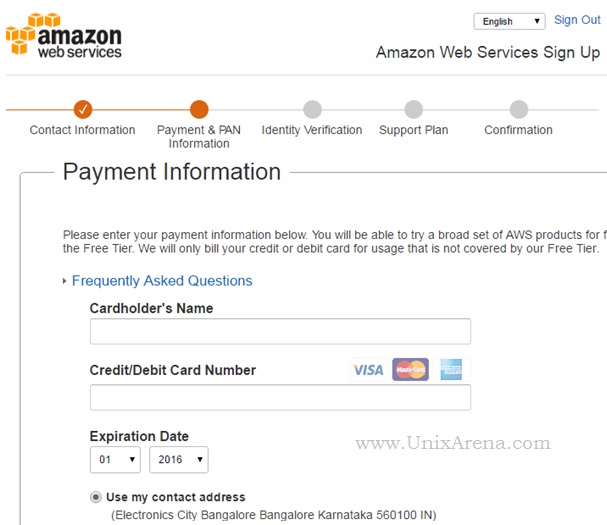
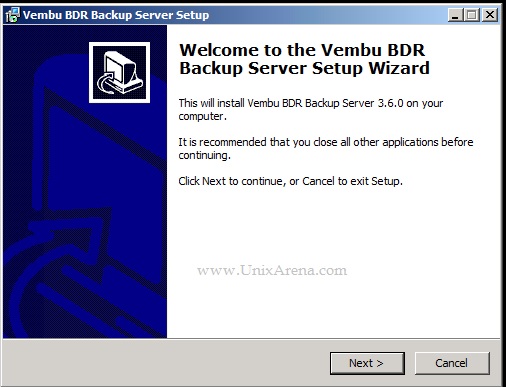
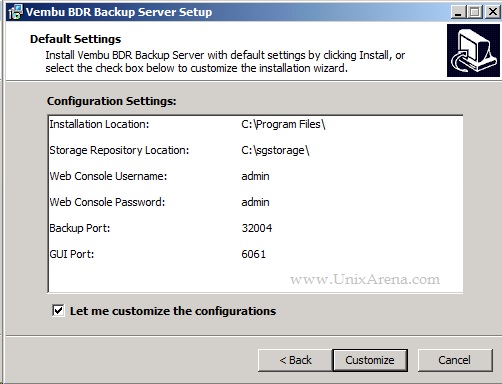
NAKIVO Backup & Replication v6 has been released with capability of supporting native backup and replication of AWS EC2 instances. NAKIVO Backup & Replication v5 supports only VMware vSPhere. There are lot happy customers who benefited using NAKIVO Backup & Replication v5 including companies like elogic , afrihost and systemc. Nakivo impressed most of the customer with easy web interface, data compression, De-duplication and network acceleration technologies to speed up the WAN backups . NAKIVO Backup & Replication provides wonderful web-interface for reporting and NAKIVO alerts can be configured via email. NAKIVO’s continuous product development is one of the most important factor to choose this product. NAKIVO Backup & Replication started supporting VMware vSphere 6.0 within few weeks after the release.
NAKIVO Backup & Replication v6 has been release many more features including support of Amazone AWS EC2. Let’s explore the NAKIVO Backup & Replication for Amazon EC2.
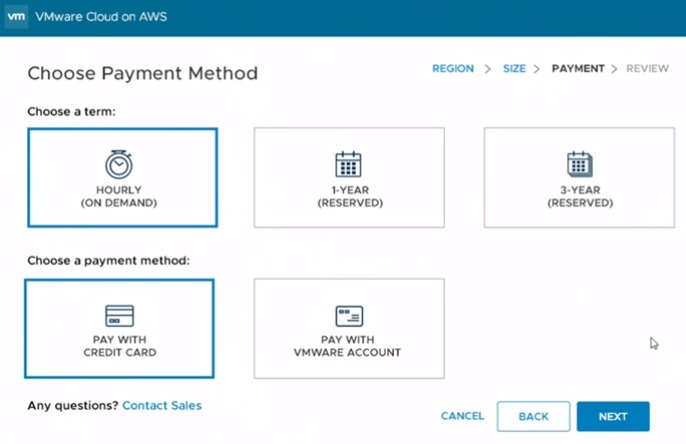
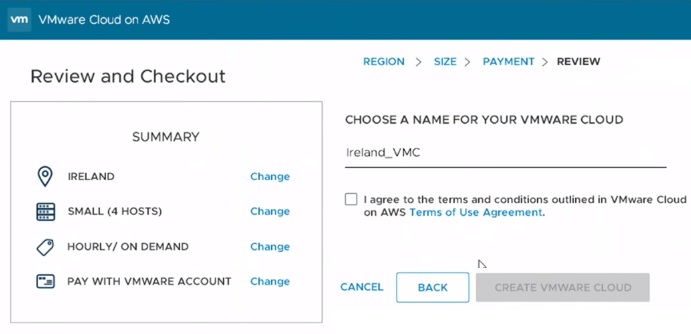
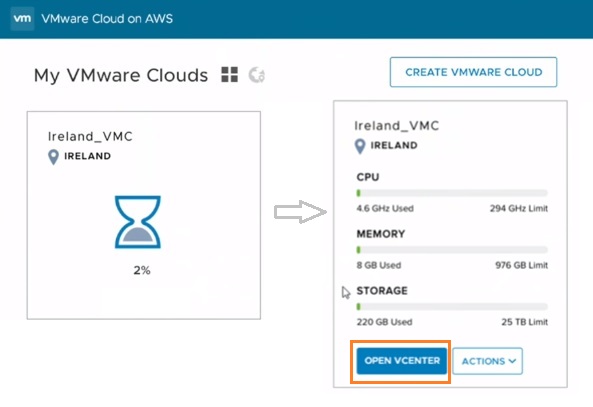
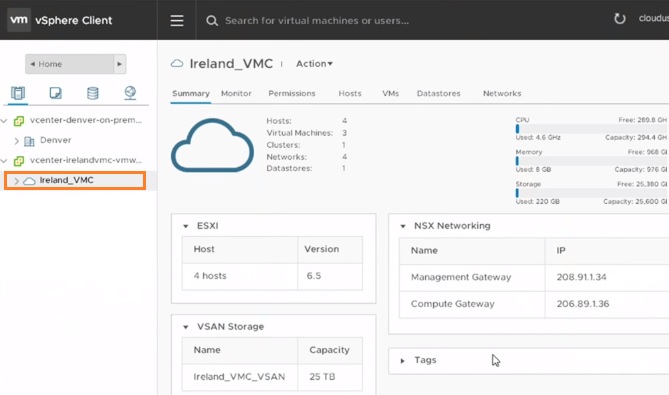
NAKIVO – Amazon EC2 support
-
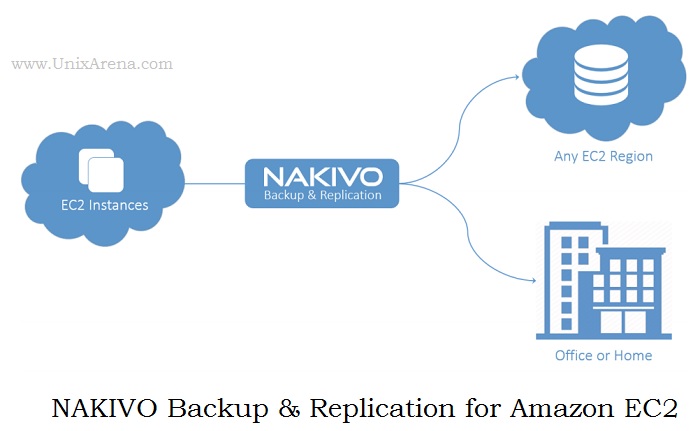
Backup:
- Save backups of your AWS EC2 instances within the same region, across regions, or offsite. Note that NAKIVO supports file recovery , application object recovery and full recovery.
-
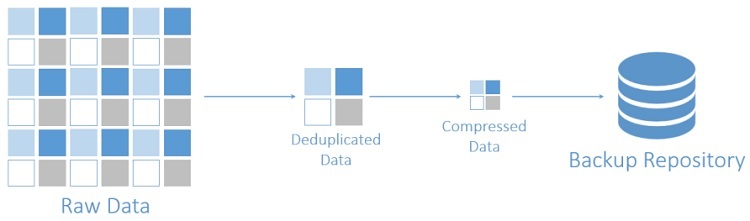
AWS EC2 Backup Deduplication
- NAKIVO Backup & Replication automatically deduplicates all AWS EC2 backups across entire backup repository. It also compress the deduplicated blocked to ensure that the least amount of space is used by the backup repository.
-
Network Acceleration :
- NAKIVO Backup & Replication can use compression and traffic reduction techniques to speed up data transfer. On average, this results in a network load reduction of 50% and a data transfer acceleration of 2X when running backup across WAN.

-
Backup copy :
- A special job type that enables copying backups between backup repositories. You can store a primary backup of your EC2 environment in the same region, and archive it to other region or offsite. There might be a chance that AWS EC2 backups can be damaged, accidentally deleted, or become unavailable due to various reasons. Backup Copy jobs, send copies to different regions, accounts, or to your office or home, copy an entire backup repository or only selected backups, or even set a different backup retention policy for your backup copies. These archive backup can be retrieved on need basis. This is similar to Veritas Netbackup vault but in simple way.

-
Replication:
- Synchronize your instances into a ready-to-use AMIs in the same or different region. You can recover a full instance within minutes. AWS EC2 instance replication supports live applications with VSS. AWS EC2 instance replication creates and maintains identical copies of your Amazon instances (aka replicas). For each instance replica, you can save up to 30 recovery points. In case source instances are lost or damaged, you can instantly recover by powering on instance replicas.
- Granular recovery:
- Recover individual files, Exchange emails and Active Directory objects.You can easily browse, search, forward, and download files and objects right within the product Web interface, without recovering the full AWS EC2 instance first. This feature is purely agentless and works out of the box for both Windows-based and Linux-based instances

-
Full recovery:
- If a backed up AWS EC2 instance is accidentally damaged or deleted, you can recover the instance from its backup in just a few clicks, regardless of where your backup repository is located. The instance will be recovered in exactly the same state as it was during the backup and will appear in the region that you select for recovery.

-
Application-aware Data Protection
- NAKIVO Backup & Replication performs application-aware backup of Windows-based and Linux-based AWS EC2 instances when you use the following applications and databases. This ensures that application and database data is always stay consistent.
- Microsoft Exchange
- Active Directory
- MS SQL
- Oracle
- Microsoft SharePoint
- Other supported applications.
- NAKIVO Backup & Replication performs application-aware backup of Windows-based and Linux-based AWS EC2 instances when you use the following applications and databases. This ensures that application and database data is always stay consistent.
-
Multi-threading
- This feature allows you to run multiple backup and replication, and recovery jobs simultaneously, which speeds up data processing and shortens the time windows allocated to data protection.
-
Web-UI:
- The simple and intuitive Web interface enables managing all aspects of data protection at any time and from anywhere, on a tablet. This saves hours of time spent on backup administration.
Adding to the above listed features,
NAKIVO Backup & Replication can automatically create, encrypt, and upload support bundles to a NAKIVO support server. This helps NAKIVO team to quickly identify and resolve support issues. It also supports HTTP APIs automation which enable you to automate and orchestrate instance backup, replication, and recovery. This can reduce the data protection cost. NAKIVO Backup & Replicaition supports NAS storage from Synology and Western digital. To know more about NAKIVO Backup & Replication for AWS , Please visit http://nakivo.com.
All the images and notes were taken from http://nakivo.com/.
The post NAKIVO Backup & Replication for Amazon EC2 – Overview appeared first on UnixArena.